In 2025, the National Vulnerability Database published more than 48,000 new common vulnerabilities and exposures (CVEs), reflecting the impact of automated and AI-powered tools on vulnerability discovery. For security teams, however, knowing about new vulnerabilities isn’t enough; they must translate each disclosure into robust detection logic fast enough to protect large, complex systems.
At AWS, we built RuleForge, an agentic-AI system that generates detection rules directly from examples of vulnerability-exploiting code, achieving a 336% productivity advantage over manual rule creation while maintaining the precision required for production security systems and enhanced customer security.
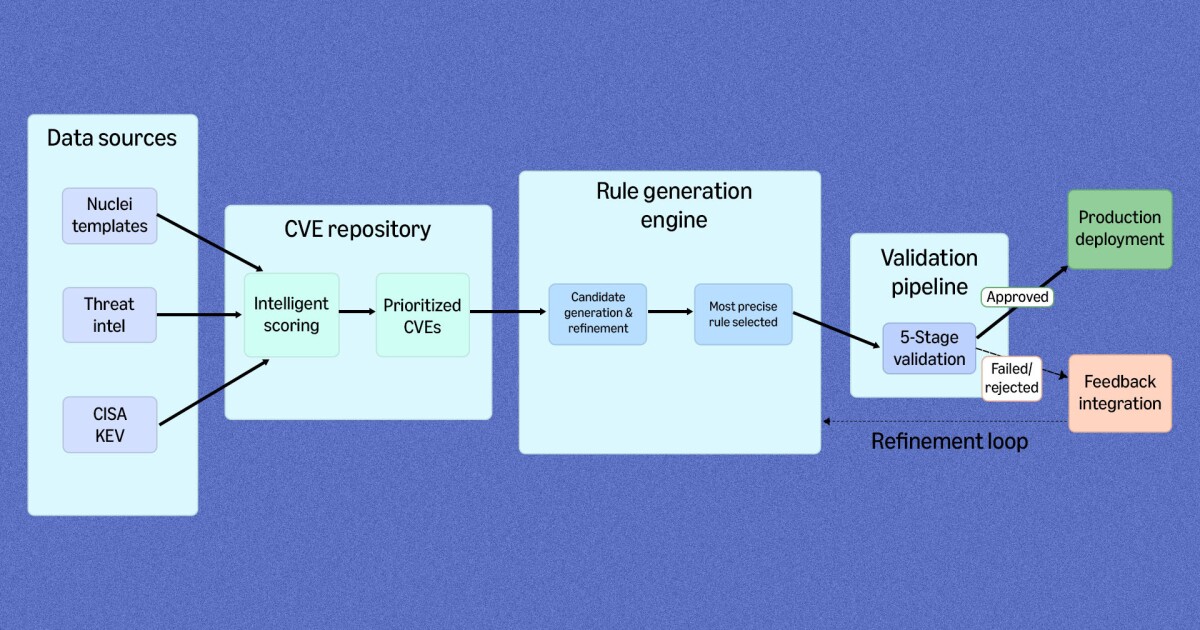
RuleForge architecture showing CVE repository, rule generation, validation, and feedback integration components.
Closing the gap between disclosure and defense
At Amazon, detection rules are written in JSON and applied to data such as requests to MadPot, a global “honeypot” system that uses digital decoys to capture the behavior of malicious hackers, and likely exploit attempts flagged by our internal detection system, Sonaris. We expect the number of high-severity vulnerabilities published to the NVD to continue to grow, which means that AI-powered automation is essential for security at scale.
By automating rule generation, we’re closing that gap while expanding our coverage. Our teams can now turn high-severity CVEs into validated detection rules at a pace and scale that would be impossible with traditional methods, providing more comprehensive protection for customers.
The manual-detection rule workflow
Before RuleForge, creating a detection rule for a new CVE was a multistep, analyst-driven process:
Download and analyze. A security analyst located publicly available proof-of-concept exploit code — code that demonstrates how to trigger a vulnerability — and studied it to understand the attack mechanism, inputs, and expected behavior.
Write detection logic. The analyst authored a rule to catch malicious traffic targeting the vulnerability, then wrote queries to measure the rule's accuracy against traffic logs.
Validate and iterate. The analyst ran those queries, reviewed the results, tuned the rule to reduce false positives, and repeated until the rule performed well enough for production.
Peer review and deploy. Finally, the analyst submitted the rule for code review by another security engineer before deployment.
This workflow produced high-quality rules, but the time investment meant the team had to carefully prioritize which vulnerabilities to cover first.
Reframing rule creation as an agentic-AI pipeline
RuleForge reimagines this workflow as an agentic-AI system — a set of specialized AI agents that collaborate to generate, evaluate, and refine detection rules, with humans remaining in the loop for final approval. Rather than attempting to solve the end-to-end problem with a single model, RuleForge decomposes the task into stages that mirror how human experts work:
Automated ingestion and prioritization. RuleForge downloads publicly available exploit proof-of-concept code demonstrating how to target a specific vulnerability. It scores each exploit using content analysis and threat intelligence sources. This ensures that rule generation focuses on the threats that matter most.
Parallel rule generation. For each prioritized CVE, a generation agent running on AWS Fargate with Amazon Bedrock proposes multiple candidate detection rules in parallel. Each candidate can be refined across several iterations based on feedback from later stages, enabling the system to explore different detection strategies before selecting the most promising ones. Instead of relying on one expert working rule by rule, RuleForge treats detection engineering as a pipeline where AI proposes options and humans decide what ships.
AI-powered evaluation. A separate evaluation agent reviews each candidate. This is one of RuleForge's key innovations: rather than having the generation model judge its own work, RuleForge uses a dedicated "judge" model to score each rule on two dimensions that human experts use to assess detection rules:
Sensitivity: What is the probability that this rule will fail to flag malicious requests described in the CVE?Specificity: What is the probability that this rule targets a feature that correlates with the vulnerability rather than the vulnerability itself?
Multistage validation. Rules that pass the judge move through a pipeline of increasingly rigorous tests. Synthetic testing generates both malicious and benign test cases to verify basic detection accuracy. Rules are then validated against traffic logs, such as those from MadPot, to confirm they perform as expected. Rules that fail at any stage get sent back to the generation agent with specific feedback explaining why, creating a closed loop of improvement.
Human review and deployment. The best-performing rule enters code review, just as before. A security engineer reviews it, and any feedback goes back to the generation agent for revision. Human judgment remains the final gate before production deployment.
A depiction of RuleForge's five-by-five generation strategy, showing five parallel rule candidates, their confidence scores, and their iterative refinement. The system generates multiple candidates simultaneously and selects the best performer based on validation results.
Why a separate judge model matters
When we asked the rule generation model to report its confidence in its own candidate rules, it thought almost everything it produced was good. This aligns with research showing poor LLM calibration on security topics.
The solution was separating generation from evaluation. Using a dedicated judge model reduced false positives by 67% while maintaining the same number of true positive detections.
Two main design choices made the judge effective:
Negative phrasing improves accuracy. Asking "what is the probability that the rule fails to flag malicious requests?" produces better calibration than asking "what is the probability that the rule correctly flags all malicious requests?" Given that LLMs tend toward affirmation, framing the evaluation as a search for problems yields more honest assessments.
Domain-specific prompts outperform generic ones. Simply asking the model to rate its overall confidence in a rule produced poor calibration. The questions that worked encoded what security engineers actually look for: whether the rule targets the vulnerability mechanism itself versus a correlated surface feature and whether the rule covers the full range of exploit variations.
The system also generates reasoning chains explaining its scores. We evaluated those reasoning chains against human assessments and found that the AI judge's reasoning matched expert human reasoning for six out of nine rules. For example, when a human evaluator noted, "That SQL injection regex is too loose," the judge had independently determined that "the regex pattern will catch any query parameter with a single quote, which is broader than just the specific vulnerability."
Results and what’s next
We deployed the confidence scoring system in August 2025, accelerating how quickly our analysts can deploy new detection rules. Over the final four months of the year, RuleForge enabled our team to produce and validate rules 336% faster than it could manually, while maintaining the high accuracy required for production security systems. By shifting analyst focus from authoring to review, we’ve multiplied overall throughput without compromising quality. We’re closing the gap between vulnerability disclosure and defense more effectively than ever before and ensuring that the managed protections that help safeguard customer workloads on AWS are updated faster and cover more high-severity CVEs.
RuleForge demonstrates that agentic AI can augment human security expertise at production scale while meeting precision requirements. The key innovations are architectural: separating rule generation from rule evaluation, using multiple specialized agents rather than a single model, and keeping humans in the loop for final approval. As the rate of vulnerability disclosures continues to accelerate, these design principles will help us keep defenses current.
For a deeper look at the technical details behind RuleForge, including the evaluation methodology and experimental results, see our paper on arXiv.








Comments (0)